
网站地图Sitemap
网站地图 一、什么是网站地图? 网站地图,又称站点地图,它就是一个页面,上面放置了网站上所有页面的链接。大多数人在网站上找不到自己所需要的信息时,可能会将网站地图作为一种补救措施。搜索引擎蜘蛛非常喜欢网站地图。 一、功能 网站地图是一个网站所有链接的容器。很多网站的连接层次比较深,蜘蛛很···
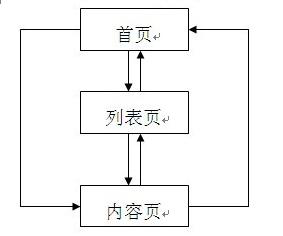
网站地图 一、什么是网站地图? 网站地图,又称站点地图,它就是一个页面,上面放置了网站上所有页面的链接。大多数人在网站上找不到自己所需要的信息时,可能会将网站地图作为一种补救措施。搜索引擎蜘蛛非常喜欢网站地图。 一、功能 网站地图是一个网站所有链接的容器。很多网站的连接层次比较深,蜘蛛很···

网站导航的目的就是帮用户更快找到想要浏览的网页,想要查找的信息,基本上每个网站都有自己的网站导航系统。而对于网站管理者,导航也无非是想让用户的浏览,提升用户网页停留时间、减少跳出率、提高PV。优化网站导航是每个网站都必须做的,那么我们到底要如何优化网站的导航呢?我们一起来看看。对网站导航的误···
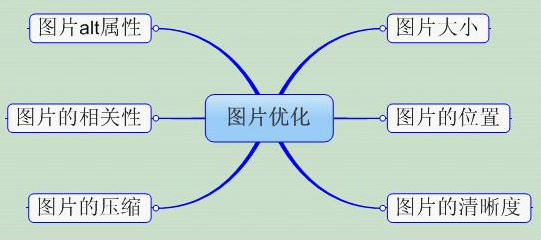
内容图片优化 1,图片的尺寸和大小图文并茂是百度和用户喜欢的形式,但运用图片的时候应注意图片的大小和尺寸。百度在搜索结果页展示图片的时候,实际上不是所有页面有图就给出显示,展示图片的一个规则就是图片大小接近121:75,站长可以根据此规则调节好图片尺寸。一是给网站服务器减压,第二是不拖累网···
长尾关键词流量占据全站流量的80%,长尾关键词优化主要注意长尾词挖掘、长尾词布局、长尾词页面内容编辑、长尾词推广和外链。

1、长尾词挖掘可以借助百度下拉框、百度相关搜索、搜狗问问、百度知道、百度推广助手等前面介绍的关键词挖掘工具。挖掘好的关键词用电子表格保存筛选,去除重复的以及选择放在网站上的长尾词。
2、按照长尾关键词竞争度依次布局栏目页和内页关键词。布局关键词按照首页、栏目页、内页优先等级依次布局。栏目页关键词是首页关键词的扩展,内页长尾词是栏目关键词的扩展。
3、内容编辑。网站长尾关键词页面内容一定要是有价值的内容,能有别人没有的内容,并且能解决用户大部分问题,或者采用更多元素方便用户阅读。
4、推广。推广的方式有很多,主要目的是让用户点击进入页面浏览,用户的点击能增加点击权重,并且促进关键词页面首页的排名。搜索引擎会把收到用户关注更多的页面更快的收录和的排名。推广方式包括QQ群、QQ邮件、QQ空间、微博、微信、软文外链等。
5、外链。外链的作用是推广和传递权重,偏向与传递权重。网页要达到收录和排名必须要有一定的权重值,外链能从站外传递一部分权重值推动页面收录和排名。
6、记录该关键词和其链接。在内容页面的关键词,我们称之为长尾关键词。我们建议你要有一个长尾关键词及其链接的列表。把这个关键词和其链接,记录到你的长尾关键词记录单里,以方便其他发其他文章时锚文本的使用。
7、强调关键词:
(1)注意关键词密度,尽量在每段中都出现该关键词。
(2)在该关键词出现的个地方,给它加黑。
(3)文章标题,给一个H标签,可以是H1,或H2。
(4)适当的在内容里出现一些相关关键词。
8、写标题和关键词标签。注意,一个页面,往往只集中精力于一个关键词。一个内容页面可以实现一个关键词的,就非常好了。
所以,内容页面的标题和关键词写法就比较简单了 例子:如果你要充分强调网站的主目标关键词,你可以把那个词放在每个页面的关键词标签里。如网站的源代码:描述标签,如果可以自定义,则针对关键词展开写80个字左右,本关键词在描述标签里重复2-3次。如不能自定义,则可以不用描述标签。
9、相关。用户在看完你的内容后,会选择离开或继续浏览。如果你有更多精彩的内容,别忘了在文章结尾给用户。有效的相关可以减少搜索跳出率注意事项.
通常网站内页排名是主站收录三个月以后,内页的收录周期是三个月。所以内页的标题和内容不要轻易修改,但如果推广和外链效果好会缩短内页排名周期。
