
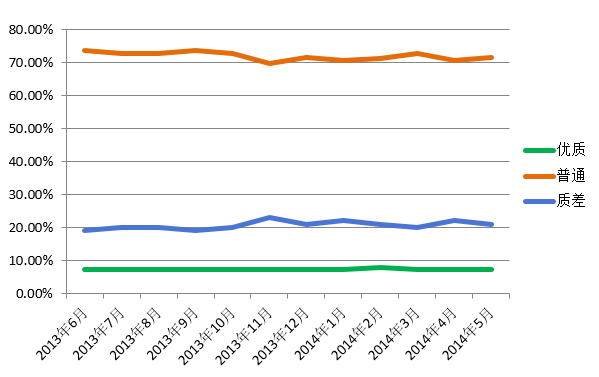
网页质量是一个网页满足用户需求能力的衡量,是搜索引擎确定结果排序的重要依据。在网页资源内容与用户需求有相关性的基础上,内容是否完整、页面是否美观、对用户是否友好、来源是否权威专业等因素,共同决定着网页质量的高低。 对于搜索引擎来说,给用户呈现的网页质量直接影响了终的搜索效果和用户的需求满足;···
通常来说,在网站的建设过程中,重复内容的产生很难避免,但是重复内容在很大程度上会影响网站在搜索引擎中的表现。今天和大家探讨的内容就是重复内容产生的原因以及解决方法。 产生重复内容的主要原因 1、正文内容越少相似度就会越高,相似度越高网站降权就越严重。主要表现在产品类网站,为什么呢,因为大多数···
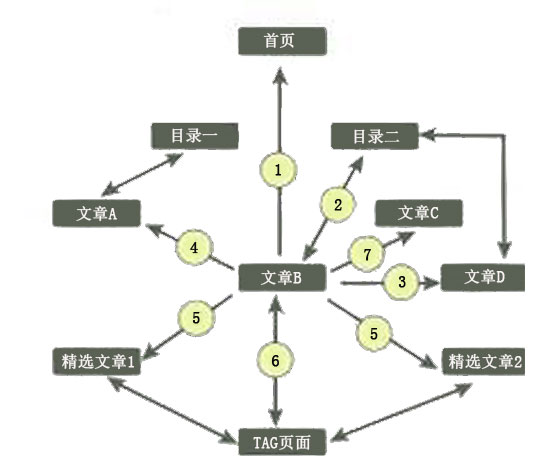
关键词布局策略 对于大多数SEOer来说,做网站优化就是做关键词排名,在关键词优化中,关键词的布局应该是我们seo优化人员应该优先考虑的一点。要想使网站排名稳定上升,必须站内+站外同步做起。竞争力不大的关键词,通过外链便可以把词做起来,再通过高质量的友情链接便可以使排名稳定,至于网站中比较难···
一、域名的选择 选择域名非常重要,因为他是网站优化步。注册域名的时候我们首先找与主题相关域名,中文全拼音,其次选择英文,如果没有,请选择域名长度较短的 域名是衡量SEO效果的必要因素、虽然对SEO的效果的影响并不是很大,但是我们还是必须遵循,一定程度会利于后期的优化传播。 二、空···
挖掘关键词是SEO的基本功,下面常用的关键词挖掘工具。
1、百度、好搜、搜狗下拉框和相关搜索
通过下拉框和相关搜索搜集长尾词的方法是一级一级搜集,比如搜索SEO,然后再搜索SEO的下拉框里面的SEO技术。下拉框和相关搜索往下搜集三个层级,三个层级以外的长尾词相关性比较低,百度相关搜索的相关性低于搜搜问问下拉框的相关性。
2、、百度知道
进入百度知道(zhidao.baidu.com)搜素关键词,寻找前两页知道问答标题,搜集作为网站长尾关键词。
3、百度推广助手
百度推广助手有大量的长尾关键词,并且有更加详细的统计标注,比如转换率高或者潜力比较大。
4、百度指数
通过百度指数可以挖掘跟这个关键词相关的热门关键词和上升快检索词,长期关注并更新这些关键词有助于跟随用户当下需求从而提升排名。
5、搜狗问问
搜狗问问的搜集方法跟百度的类似,百度相关搜索出来的词点击进入第二层的关键词是独立相关内容的词,而搜狗问问点击某个词进入的第二级会继承级搜索词的性质。简单一点解释就是百度相关搜索不同层级之间的关键词联系很低,而搜搜问问各层级之间的长尾词联系高,所以一般使用搜狗问问挖掘的关键词更多。
搜狗问问区别去百度的另一个方面是搜搜问问更加倾向于问答。
6、分析竞争对手,研究竞争对手的目录关键词
研究竞争对手的目录导航是那些关键词,然后分析内页,整理出网站的关键词。
7、百度竞价后台的关键词工具
笔者个人认为,这些关键词其实并不难查找,大都被相关行业的seoer所熟知,既然需要竞价,那它的竞争度恐怕是相当激烈,并非是利于新手站长在起步时期便参与竞争的词汇。百度竞价后台的关键词工具可以更详细查找。(www2-baidu-com)
8、百度百科
百度百科中拥有大量用户常用词条。
9、站长工具
站长工具和爱战网都有相关的关键词扩展工具,但都是有指数的关键词。
10、5118挖词工具
通过5118专业挖词工具
