
百度移动搜索是全球大的中文移动搜索引擎,每天导向互联网的流量高达十亿级别,网站移动化势在必行。 本篇旨在为移动站站长提供权威、明确的移动搜索优化标准,帮助网站合理、可持续地提升移动流量,获得长久、稳定的发展,从而促进整个移动互联网的良性发展。技术选型 如何布局您的PC站和移动站,并表达两者之···
网站被黑有何影响?1、网站降权网站降权是重要的一个影响,因为大多数网站都有数据库和文件备份,所以不可能被黑客全部毁掉网站,所以严重的应该是网站权重下降的问题,一旦网站被黑,网站之前做的所以的关键词排名会迅速下降,甚至没有,而这个恢复时间往往很漫长,特别是对企业影响极大。2、网站信誉下降如果是一个···

什么是静态网页,什么是动态网页 想知道什么是伪静态,那么我们必须知道什么是静态和动态的,之前没有接触网站的时候,认为静态的就是没有flash多的页面,动态的就是有flash的页面,发现这真是一个片面的理解,现在才知道这并不是区别静态和动态的原理,而是通过代码来区别的 静态网站是指···
元素可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。 标签位于文档的头部,不包含任何内容。 标签的属性定义了与文档相关联的名称/值对。 定义 <meta> 元素可提供有关页面的元信息(meta-information),比如针对搜···
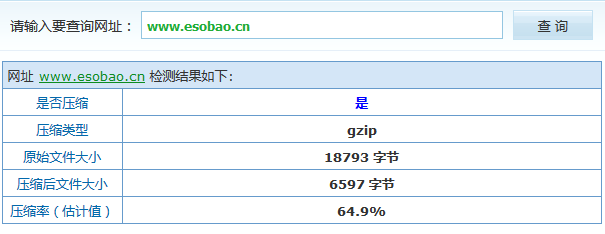
Gzip压缩 GZIP是GNUzip的缩写,它是一个GNU自由软件的文件压缩程序。它是Jean-loupGailly和MarkAdler一起开发的。次公开发布版本是1992年10月31日发布的版本0.1,1993年2月发布了版本1.0。 GZIP早由Jean-loup Gailly和M···
robots.txt文件详细解说 1. 什么是robots.txt文件? 搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做 robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓···
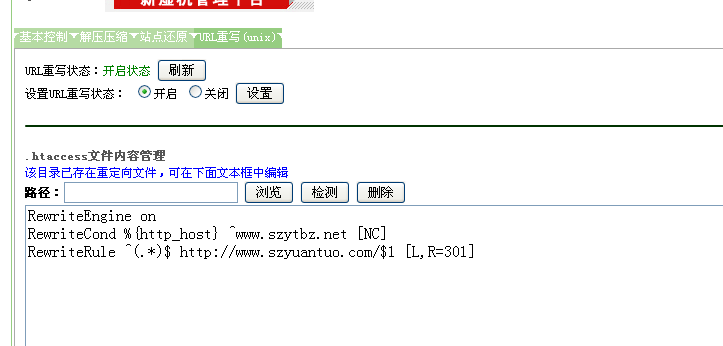
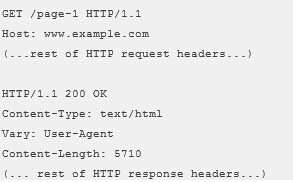
网址规范化 之 301转向: ①:什么是301转向? 301转向又称301重定向、301跳转,是用户或蜘蛛向网站服务器发出访问请求时,服务器返回的HTTP数据流中头信息部分状态码的一种,表示本网址性转移到另一个地址。 另外,还有其他的网址转向方法,例如:302转向、javascript···

404页面的概念:
当你打开某一个网站的内页页面不存在,提示页面不存在或者连接错误,该页面上可以访问到网站的其他页面,这样的页面称之为404页面。
其主要的作用是为了引导用户在那些打不开的链接上能访问到网站的其他地方,而不是让用户直接关闭窗口,有助于增加用户体验度,同时对搜索引擎也是有好处的,可以让蜘蛛对网站爬的更深点。不会因页面错误而中止抓取!
404页面注意的地方:
在有些站长喜欢自作聪明,把那些页面不存在时设置成返回200状态码,这样以为能让搜索引擎知道这个页面是正常的,其实大错特错,这些页面都是相同的内容,搜索引擎对于那些多个url都是大量重复的内容这种是非常避讳的。
部分网站把404页面设计成定时,时间到后自动返回首页,这种也是和上面一样,也会让搜索引擎判断错误,后都会被误判为重复内容,后果可严重了,可以导致网站只收录内页,不收录首页!
404页面设计:
互联网上网站上各种各样的404页面,玲琅满目,作为一名SEO人员,到底应该设计怎样的404页面才符合SEO呢?其实抓住重要几个就可以了。
1.404页面和其他文章页面一样,保持一样的模板,风格,logo等,让用户知道还在这个网站上面;
2.404页面应该清晰醒目的提示请求的信息内容不存在或已被删除或被转移到新的地址上面,让用户知道即可;
3.还可以在上面加上一些可以通向网站其他地方的链接,如内导航,首页,网站地图,也可以加一个”您可能还感兴趣的”链接诱饵;
把这三点考虑进去,然后在针对自己的网站设计404页面,那就简单多了,不紧给网站有一个良好的用户体验,还可以符合搜索引擎!
怎样找出网站中的404错误?
1.直接的方法: 查看网站的访问日志;
2.如果网站有记录404的统计可以方便很多.
对于网站中大量404死链的解决:
如上面我们提到的, 大量404影响用户和搜索引擎的体验, 提交死链删除很有必要.
收集死链是个复杂的问题, 目前百度还没有通配符的方式提交死链.
1.如果站点同目录下的死链可以根据死链的url规则来判断并找出这些死链;
2。对于泛域名解析导致的死链, 每个泛域名都是一个相对独立的站点, 少量的收录可以用手工的方式来收集, 但是大量收录只能借助第三方工具从百度都搜索引擎中抓取出来.
