做SEO网站推广,都知道“内容为王,外链为皇”。百度去年7月发布公告称,新的超链算法仅信任小范围内的优质重要外链,垃圾外链无法提升权重,而且容易被K站。那外链还能做吗,当然要做,酒香也怕巷子深,对于每个站长来说,除了做好网站内容和服务外,还要让更多的人了解。根据2016年的网络环境,整理了这份外链指南,希望对大家的SEO之路有些帮助。
1、媒体平台投稿
写好的软文,加上链接和关键词,让那些热门的媒体平台收录后,就会被大量转载。媒体平台是很多小网站的信息源,具有非常广的传播空间,有利于增加外链,即使链接在传播时被抹去,软文中的关键词还是会被收录,并提升搜索排名的权重。这些媒体平台往往属于百度新闻源,新闻源对于网站权重提升会有很大帮助。
常见媒体平台包括:
搜狐媒体平台 http://mp.sohu.com/
今日头条 http://toutiao.com/cooperation/
百度百家 http://baijia.baidu.com/
网易媒体开放平台 http://dy.163.com/wemedia/
一般来说媒体平台的入驻要求会比较高,审核更严格,对于草根站长来说会有一定难度,但也并非高不可攀,只要有足够的耐心,就一样可以入住。下面以搜狐自媒体为例,给大家介绍下具体的入驻方法。
进入搜狐媒体平台页面后(mp.sohu.com),有自媒体的“申请入驻”按钮,进入后步是信息登记,需要提交姓名、身份证号及照片等信息,第二步是自媒体账号申请,需要提交辅助材料。辅助材料很重要,如果你已经有名气或有自己的微信公众号,那就容易通过,如果没有的话,需要在一些站点上发表过署名文章,提交相应链接就可以了。 当然,如果资金允许的话,淘宝上会有不少提供此类服务的商家,效率可能。
2、百度推广
在百度产品中建设的外链都属于高质量外链,可建外链的地方有百度百科、百度知道、百度博客、百度文库等,在百度文库和百度百科中建设的外链效果好,对内容质量的要求也高,需要人工审核。
3、友情链接
友情链接的作用依然重要,如果是新站,找些权重高的网站带带,发展起来会更顺利。
4、问答网站外链
问答类的外链权重也是很高的,相关网站包括百度知道、爱问知识人、搜搜问问、天涯问答、PCauto快问、爱打听、淘宝问答、中华网问答、丁丁问吧、360问答等等。不少问答站看似不能留链接,其实是需要一些技巧,比如用手机提问,PC回答,只要多去测试,就能找到方法。
5、分类信息及商铺
常用的分类信息站包括赶集网、58、百姓网等,其价值在于它可以带来精准流量。在分类信息站上发布基于用户需求的帖子,以长尾关键词做标题,就可以引来精准流量。如果在内容中加入外链,还能起到提升权重的作用。
如果发布的信息量足够大,实现长尾词霸屏也是有可能的。曾经有一家网站使用长尾词做了3000个商铺,2000多个分类信息,每个商铺中都留下了链接和联系方式,能带来的流量就非常可观了。
6、网摘和搜藏
网摘和搜藏在搜索引擎排名中的地位是比较高的,作为内容聚合站,很多内容是网友的真实分享,因此权重会比较高。多积攒一些账号,发布有价值的内容,对于网站推广还是很有帮助的。
7、在论坛及社区留外链
基于百度新的垃圾外链算法,简单发论坛外链的作用已几乎为零,所以那种签名、评论之类的外链就不要再用了。怎样让论坛和社区继续发挥外链作用,这里需要一些方法:
(1)、直播贴。开个新帖,设定某一主题,不断释放价值,推送行业相关信息或者经验,在直播的过程中把这个帖子搞火,然后在帖子中嵌入自己的网站品牌词,在释放价值的过程中不断曝光品牌。
(2)、答疑帖。设定自己是行业专家,昵称要与品牌有关,然后开设一个答疑帖,回答新手提出的问题,在问答的过程中促成顶贴,这样帖子火了,品牌也曝光了。
(3)、资源帖。任何一个行业都有一定的资源需求,比如说制作一些资源,将作者的网址加在下面,注明,谁想免费使用,需要保留作者网址,然后把这些资源免费传播出去,就可以坐等收链接了。
或者我们可以将这些资源搜集起来打包并加入广告,以免费的方式分享出去,要求网友留言留邮箱,实现顶贴效果,帖子火了,就可以实现引流。
8、博客外链
现在传统博客的外链作用已经很小了,需要达到足够的量才能有效果。同时不要把眼光局限在新浪、网易、凤凰、搜狐这些平台,很多社区的博客平台影响力也很大,比如:人人小站、豆瓣小组、西祠部落、太平洋博客、宝宝树博客,平台非常多,只要多观察,就会发现大量的外链平台。微博外链的作用正在上升,粉丝经济的影响力相当强大,需要多关注。
如何寻找外链平台对于很多新手来说是很困难的事情,下面是寻找外链的一些方法。
1、简单直接domain:网址,这个可以基本看到对手所发外链信息,当然在百度站长工具平台推出的今天我们也可以在这个里面查询下效果。因为这里可以看到该网址所有的外链接。
2、学会使用Intitle(注:限制搜索范围在标题之中) 例子:intitle:关键词 (其实可以直接搜索外链平台汇总)
3、跟同行朋友互相交换资源
从事seo行业的朋友都知道,仅靠自己一人之力是寻找不到多少高质量外链资源的,这个时候我们就需要多与同行朋友交流互换资源。
4、友情链接平台
代表网站go9go友情链接平台 、chinaz站长交易平台等,需要找更多的直接百度搜索 “友情链接平台“就可以啦。友情链接跟网址导航站一样,都是输出连接站这类网站往往权重都特别高,这类网站通常收录及快,无疑是一条高质量的外链。
5、开放分类目录
代表网站chinadmoz开放分类目录网站、35分类目录等,同上输出类网址,因为网站本身的特殊性加上目前有限的开放目录网站,因此这类资源变得尤为珍贵。
6、网址导航站
代表网站:hao123,输出类型网址同样属于高质量外链,我们要尽可能的区多做几个网址导航的外链。
7、门户站博客
新浪博客、搜狐博客、网易博客、百度博客、和讯博客 具体百度搜索博客网站大全就出来几百个。注:新浪博客基本秒收,用来做长尾词的排名还是可以的。
8、行业站博客/商铺
如阿里巴巴免费商铺、同行业B2B网站商铺等。这类网站跟博客一样属于二级域名范畴,我们在建立了商铺后不仅对我们的产品有推销作用,同时还给自己增加了一条外链。
9、网络收藏夹/书签
乐收收藏夹、qq书签等。每天做几条收藏效果也不错。
10、各大网站/博客评论留言
闲暇之余去热门的博客或各大热门的网站去留言、回复主题等。
11、论坛社区
论坛社区的挖掘方法第二条已提供:百度搜索:intitle:关键词 Powered by discuz!
12、问答平台
奇虎问答、搜搜问问、天涯问答、百度知道、新浪爱问等。如何去做问答网上有很多教程,大家自己去观阅。
13、视频站
优酷视频、六间房视频、土豆视频;平时没事随手到车间用手机拍下产品的制造过程、使用过程等,然后在发布到各大视频网站,顺便加上你的网址链接。
14、分类信息/b2b平台
如58同城、赶集网具体可以百度分类信息网址大全,b2b平台如阿里巴巴、慧聪、一呼百应等
15、招聘类
招聘类网站在填写公司简介和公司招聘信息时都是可以留入网址信息的,很多招聘类网站权重非常高,所以可以好好利用下了,在招聘的同时不妨给我们的网站留个外链。
16、门户新闻投稿/付费投稿
门户网站投稿:比如a5投稿、同行业门户站投稿等;付费投稿就是常见的买各大新闻网站的新闻外链,这个笔者不。
17、RSS收藏/网摘
抓虾 鲜果等
18、查询缓存
说直接点就是去各大在线站长工具网站查询网站收录、外链什么的会产生一个缓存,这时候正好被百度蜘蛛爬取然后收录到数据库,比如
这种现象就是早期作弊工作喜欢用的将网址提交到各大在线站长工具网址里,然后一下可以增加N条外链等。这里警示我们一点不要太刻意的整这个东西,有时候查查被搜索引擎收录了起一个引蜘蛛的作用。
19、百度产品
百度开放平台自己去琢磨,百度知道、百度文库、百度贴吧、百度百科、百度空间等
搜索引擎优化(Search engine optimization,简称SEO),指为了提升网页在搜索引擎自然搜索结果中(非商业性推广结果)的收录数量以及排序位置而做的优化行为,这一行为的目的,是为了从搜索引擎中获得更多的免费流量,以及的展现形象。而SEM(Search engine marketing,搜索引擎营销),则既包括了SEO,也包括了付费的商业推广优化。
SEO自从1997年左右出现以来,逐渐分化成两类SEO行为:一类被称为“白帽SEO”,这类SEO起到了改良和规范网站设计的作用,使之对搜索引擎和用户更加友好,并从中获取更多合理的流量。搜索引擎鼓励和支持“白帽SEO”。另一类被称为“黑帽SEO”,这类SEO行为利用和放大搜索引擎的策略缺陷(实际上完美的系统是不存在的)获取更多用户访问量,而这些更多的访问量,是以伤害用户体验为代价的,所以,面对后一种SEO行为,搜索引擎会通过一些策略进行遏制。
搜索引擎与SEO行为间是一种良性的共生关系,比如很多优质的网站是用Flash或者Ajax做的,搜索引擎就无法很好的爬取和索引。建站者在了解了SEO的一些基本原理后,可以通过对网站的合理优化,使这些优质资源的发挥其检索效果,改善用户的搜索体验。同时,对于中国这样的新兴市场,传统的中小企业对于如何触网,如何做互联网营销,并无多少经验,在广大的互联网创业者中,对于如何SEO也充斥着矛盾的舆论和猜想。让更多人了解搜索引擎的工作机制,引导广泛合理的SEO行为,让认真做原创优质内容的创业者得到更多流量,令抄袭抓取别人内容的建站行为得到警惕,是百度作为中文搜索领域的应有的责任和义务,只有这样才能有效支持互联网创新力量,使互联网生态圈得到更加健康有序的发展。
需要指出的是,此次发布的《搜索引擎优化指南》,虽然听取了部分站长的意见和建议,但仍有很大的提升空间。未来,我们会收集更多的建设性意见,来不断的完善这一指南。
前期准备
域名注册
域名是用户对网站的印象,能否让用户迅速记住域名对网站发展非常重要。建议注册域名时选择容易让用户记忆、容易产生信任感的域名,这样可以提高回头率,并方便用户。
• 域名尽量简短,越短的域名,用户的记忆成本就越低
• 域名可以和网站主题或网站名称相呼应,让人看到域名就能联想到网站内容,比如使用公司名称、商标、网站名称或者公司产品等信息来选择域名
• 使用何种形式的域名后缀对百度网页搜索没有影响,但域名后缀也需要考虑方便用户记忆。.com、.cn、.net等常见的域名后缀用户更容易记忆,一些不常见的后缀可能会让用户产生不信任感,增加用户的判断成本。
服务器、空间租用
服务器、空间的速度和稳定性直接影响网站的用户体验,也会影响搜索引擎的抓取。建议选择服务稳定、速度快的服务器或者空间。
• 选择有实力的正规空间商
服务器和空间的稳定性需要一定的技术实力来,一些没有实力的空间商,可能无力提供良好的服务,服务的稳定性无法。甚至有空间商为了节省资源,故意屏蔽掉Baiduspider的抓取,导致网站无法被百度网页搜索收录。
• 用户的访问速度和稳定性
• 根据网站规模和要提供的服务来决定选择购买何种空间(服务器)
通常空间都会有流量、连接数以及功能上的限制,因为是多个网站共用一台服务器,稳定性会受到影响,但价格便宜;服务器各种限制较少,可以更自主的管理,但价格较贵。可以根据自己的需求来进行合理的选择。
• 根据用户群分布选择接入商
由于互通问题的存在,选择接入商也很重要,如果用户群主要在联通,就尽量选择联通访问较好的接入商,如果用户群主要在电信,则选择电信访问较好的接入商。如果用户群在全国,那就选择一家互通处理的比较好的接入商。
在此提示站长:购买之前,可以先找一两个空间商现有的客户网站,测试访问情况如何。
面向搜索引擎的网站建设
搜索引擎只是网站上一个普通的访客,对网站的抓取方式、对网站/网页的价值判断,也都是从用户的角度出发的,任何对用户体验的改进,都是对搜索引擎改进。对搜索引擎的优化,同时也会让用户受益。
面向搜索引擎的网站建设,主要分为三个部分:如何的让搜索引擎收录网站中的内容、如何在搜索引擎中获得良好的排名、如何让用户从众多的搜索结果中点击你的网站。简单来说,就是收录、排序、展现。下面我们将从这三个方面分别介绍。
良好收录
机器可读
百度通过一个叫做Baiduspider的程序抓取互联网上的网页,经过处理后建入索引中。目前Baiduspider只能读懂文本内容,flash、图片等非文本内容暂时不能处理,放置在flash、图片中的文字,百度无法识别。
建议使用文字而不是flash、图片、Javascript等来显示重要的内容或链接,搜索引擎暂时无法识别Flash、图片、Javascript中的内容,这部分内容无法搜索到;仅在flash、Javascript中包含链接指向的网页,百度可能无法收录。
我们建议:
• 使用文字而不是flash、图片、Javascript等来显示重要的内容或链接
• 如果必须使用Flash制作网页,建议同时制作一个供搜索引擎收录的文字版,并在首页使用文本链接指向文字版
• Ajax等搜索引擎不能识别的技术,只用在需要用户交互的地方,不把希望搜索引擎“看”到的导航及正文内容放到Ajax中
• 不使用frame和iframe框架结构,通过iframe显示的内容可能会被百度丢弃

上面例子中,虽然网页上提供了很丰富的信息,但由于信息都在flash中,搜索引擎无法提取,对搜索引擎来讲,这个网页没有任何内容。
网站结构
网站应该有清晰的结构和明晰的导航,这能帮助用户快速从你的网站中找到自己需要的内容,也可以帮助搜索引擎快速理解网站中每一个网页所处的结构层次。
网站结构建议采用树型结构,树型结构通常分为以下三个层次:首页——频道——文章页。象一棵大树一样,首先有一个树干(首页),然后再是树枝(频道),后是树叶(普通内容页)。树型结构的扩展性更强,网站内容变多时,可以通过细分树枝(频道)来轻松应对。
理想的网站结构应该是更扁平一些,从首页到内容页的层次尽量少,这样搜索引擎处理起来,会更简单。
同时,网站也应该是一个网状结构,网站上每个网页都应该有指向上、下级网页以及相关内容的链接:首页有到频道页的链接,频道页有到首页和普通内容页的链接、普通内容页有到上级频道以及首页的链接、内容相关的网页间互相有链接。
网站中每一个网页,都应该是网站结构的一部分,都应该能通过其他网页链接到。
总结一下,合理的网站结构应该是一个扁平的树型网状结构。我们建议:
• 确保每个页面都可以通过至少一个文本链接到达。
• 重要的内容,应该能从首页或者网站结构中比较浅的层次访问到。
• 合理分类网站上的内容,不要过度细分。
网站应该有简明、清晰的导航,可以让用户快速找到自己需要的内容,同时也可以帮助搜索引擎的了解网站的结构。我们建议:
• 为每个页面都加上导航栏,让用户可以方便的返回频道、网站首页,也可以让搜索引擎方便的定位网页在网结构中的层次。
通过面包屑导航,用户可以很清楚的知道自己所在页面在整个网站中的位置,可以方便的返回上一级频道或者首页也很方便。
• 内容较多的网站,建议使用面包屑式的导航,这更容易让用户理解当前所处的位置:网站首页 > 频道 > 当前浏览页面
• 导航中使用文字链接,不使用复杂的js或者flash
• 使用图片做导航时,可以使用Alt注释,用Alt告诉搜索引擎所指向的网页内容是什么
子域名与目录的选择
选择使用子域名还是目录来合理的分配网站内容,对网站在搜索引擎中的表现会有较大的影响。
我们建议:
• 在某个频道的内容没有丰富到可以当做一个独立站点存在之前,使用目录形式;等频道下积累了足够的内容,再转换成子域名的形式
一个网页能否排到搜索结果的前面,“出身”很重要,如果出自一个站点权重较高的网站,那排到前面的可能性就越大,反之则越小。通常情况下主站点的权重是高的,子站点会从主站点继承一部分权重,继承的多少,视子站点质量而定。
在内容没有丰富到可以做为一个独立站点之前,内容放到主站点下一个目录中能在搜索引擎中获得的表现。
• 内容差异度较大、关联度不高的内容,使用子站点形式
搜索引擎会识别站点的主题,如果站点中内容关联度不高,可能导致搜索引擎错误的识别。关联度不高的内容,放在不同的子域名下,可以帮助搜索引擎的理解站点的主题
• 域名间内容做好权限,互相分开,a. example.com下的内容,不能通过b. example.com访问
子域名间的内容可以互相访问,可能会被搜索引擎当做重复内容而进行除重处理,保留的url不一定是正常域名下的。
• 不要滥用子域名
无丰富内容而滥用大量子域名,会被搜索引擎当做作弊行为而受到惩罚。
规范、简单的URL
创建具有良好描述性、规范、简单的url,有利于用户更方便的记忆和判断网页的内容,也有利于搜索引擎更有效的抓取您的网站。网站设计之初,就应该有合理的url规划。
我们建议:
• 如果网站中同一网页,只对应一个url
如果网站上多种url都能访问同样的内容,会有如下危险:
1、搜索引擎会选一种url为标准,可能会和正版不同
2、用户可能为同一网页的不同url做,多种url形式分散了该网页的权重
如果你的网站上已经存在多种url形式,建议按以下方式处理:
1、在系统中只使用正常形式url,不让用户接触到非正常形式的url
2、不把Session id、统计代码等不必要的内容放在url中
3、不同形式的url,301跳转到正常形式
4、防止用户输错而启用的备用域名,301跳转到主域名
5、使用robots.txt禁止Baiduspider抓取您不想向用户展现的形式
• 让用户能从url判断出网页内容以及网站结构信息,并可以预测将要看到的内容
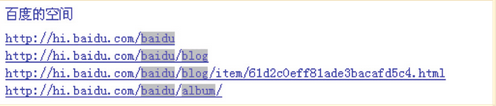
以百度空间为例,url结构中加入了用户id信息,用户在看到空间的url时,可以方便的判断是谁的空间。url结构中还加入了blog、album等内容信息,用户可以通过url判断将要看到的内容是一篇博客,还是一个相册。
• URL尽量短,长URL不仅不美观,用户还很难从中获取额外有用的信息。另一方面,短url还有助于减小页面体积,加快网页打开速度,提升用户体验。

例子中的个url,会让用户望而却步,第二个url,用户可以很轻松的判断是贴吧中关于百度的吧。
• 正常的动态url对搜索引擎没有影响。url是动态还是静态对搜索引擎没有影响,但建议尽量减少动态url中包含的变量参数,这样即有助于减少url长度,也可以减少让搜索引擎掉入黑洞的风险
• 不添加不能被系统自动识别为url组成部分的字符

上面例子中,url中加入了“;”、“,”等字符,用户在通过论坛、即时通讯工具等渠道这些url时,不能被自动识别为链接,增加了用户访问这些网页的困难度。
• 利用百度提供的URL优化工具检查
百度站长平台提供了URL优化工具,可以帮助检查URL对搜索引擎的友好程度并提出修改建议。
利用站长工具
互联网越来越庞大、复杂,百度为了的处理互联网上的信息,提供了一些的面向站长的工具,合理的利用这些站长工具,可以起事半功倍的效果。
• 百度站长平台:
登录zhanzhang.baidu.com获取更多帮助信息。
• Sitemap :
百度站长平台支持通过sitemap提交网站内容。通过sitemap可以让百度更全面更快的发现链接,使得收录更有效率。
• Ping:
Ping是针对blog内容的提交方式,实时通知搜索引擎blog上有新内容产生。目前主流的博客程序都支持ping,您只需要将百度的ping服务地址http://ping.baidu.com/ping/RPC2加入博客后台并开启ping功能即可。
• 死链删除:
百度站长平台支持通过sitemap向百度提交网站的死链列表。网站死链过多,不仅影响用户访问体验,也影响百度对网站质量的判断。通过死链删除的接口可以让百度更快更全面的发现网站死链,从而进行有效删除。
注:提交需要删除的网址后,需要做如下处理,才能被百度有效删除:
1、使用robots.txt阻止其被抓取;
2、或者返回404状态码表示当前页面不存在。
• 站长工具
-URL优化工具检查
百度站长平台提供了URL优化工具,可以帮助检查URL对搜索引擎的友好程度并提出修改建议。
-网站安全检测
百度站长平台提供工具检测网站是否被黑并提示站长,帮助修改。
♦ 什么是“网站被黑”?
网站被黑,是指黑客利用网站的程序、设置等方面的安全漏洞或管理员安全疏忽(如密码复杂度低),未经管理员授权,对网站进行了篡改。
♦ 如何处理网站被黑?
1、分析系统日志、服务器日志,检查自己站点的页面数量、流量等是否有异常波动,是否存在异常访问或操作日志;
2、检查网站文件是否有不正常的修改,尤其是首页等重点页面;
3、网站页面是否引用了未知站点的资源(图片、JS等),是否被放置了外站的异常链接;
4、检查网站是否有不正常增加的文件或目录;
5、检查网站目录中是否有非管理员打包的网站源码、未知txt文件等。
♦ 如何防止网站被黑?
1、定期检查服务器日志等方式发现问题,检查是否有可疑的针对非前台页面的访问;
2、经常检查网站文件是否有不正常的修改或者增加;
3、关注操作系统,以及所使用程序的官方网站。及时下载补丁,修补安全漏洞;必要时建议直接更新至新版本;
4、修改开源程序关键文件的默认文件名,作弊者通常通过程序自动扫描某些特定的文件是否存在来判断是否使用了某套程序;
5、修改默认管理员用户名,提高管理后台的密码强度,使用字母、数字以及特殊符号多种组合的密码;
6、关闭不必要的服务,以及端口;
7、关闭或者限制不必要的上传功能;
8、设置防火墙等安全措施;
9、若问题反复出现,建议重新安装服务器操作系统,并重新上传备份的网站文件;
10、缺乏专业维护人员的网站,建议向专业安全公司咨询;快速发现并处理被黑内容,并做好被黑的预防,非常体现一个网站的运营水平。
上述的几点仅仅是初步的参考。做好网站的安全需要站长、管理员们的不断努力。
• 百度搜索框提示功能
百度向站长开放免费“百度搜索框”代码和“百度搜索框提示”代码。
只需进行简单的设置,即可将“百度搜索框(带提示功能)”功能快速加入到您的网页中。提升用户在网站中的搜索体验。
改版/换域名
网站改版、换域名在互联网飞速发展的情况下是不可避免的,但处理不当,会造成重大的流量损失。改版、换域名需要考虑的要点就是如何老用户不流失,当用户访问旧内容时,能引导用户到新网站上对应的内容,避免出现用户访问不到以前收藏的网页的情况。
我们建议在改版或者换域名时,将旧网页301重定向到内容对应的新网页,这样百度更容易发现这个转变,并迅速的将旧网页积累的权值传递给对应的新网页。
其他建议:
• 如非必要,不要做整站内容的完全更换
网站改版或者网站内重要页面链接发生变动时,应该将改版前的页面301重定向到改版后的对应的页面
• 网站更换域名,应该将旧域名的所有页面301重定向到新域名上对应的页面
网站更换域名后,维持旧域名能稳定访问尽可能长的时间,给用户多一些时间记忆新域名
• 网站改版/更换域名后,请把新的URL/新域名下的URL,通过sitemap提交给百度,帮助百度更快发现和作出调整。
合理的返回码
百度爬虫在进行抓取和处理时,是根据http协议规范来设置相应的逻辑的,所以请站长们也尽量参考http协议中关于返回码的含义的定义来进行设置。
百度spider对常用的http返回码的处理逻辑是这样的:
• 404
404返回码的含义是“NOT FOUND”,百度会认为网页已经失效,那么通常会从搜索结果中删除,并且短期内spider再次发现这条url也不会抓取。
• 503
503返回码的含义是“Service Unavailable”,百度会认为该网页临时不可访问,通常网站临时关闭,带宽有限等会产生这种情况。对于网页返回503,百度spider不会把这条url直接删除,短期内会再访问。届时如果网页已恢复,则正常抓取;如果继续返回503,短期内还会反复访问几次。但是如果网页长期返回503,那么这个url仍会被百度认为是失效链接,从搜索结果中删除。
• 403
403返回码的含义是“Forbidden”,百度会认为网页当前禁止访问。对于这种情况,如果是新发现的url,百度spider暂不会抓取,短期内会再次检查;如果是百度已收录url,当前也不会直接删除,短期内同样会再访问。届时如果网页允许访问,则正常抓取;如果仍不允许访问,短期内还会反复访问几次。但是如果网页长期返回403,百度也会认为是失效链接,从搜索结果中删除。
• 301
301返回码的含义是“Moved Permanently”,百度会认为网页当前跳转至新url。当遇到站点迁移,域名更换、站点改版的情况时,使用301返回码,尽量减少改版带来的流量损失。虽然百度spider现在对301跳转的响应周期较长,但我们还是大家这么做。
我们建议:
• 如果站点临时关闭,当网页不能打开时,不要立即返回404,建议使用503状态。503可以告知百度spider该页面临时不可访问,请过段时间再重试。
• 如果百度spider对您的站点抓取压力过大,请尽量不要使用404,同样建议返回503。这样百度spider会过段时间再来尝试抓取这个链接,如果那个时间站点空闲,那它就会被成功抓取了。
• 有一些网站希望百度只收录部分内容,例如审核后的内容,累积一段时间的新用户页等等。在这种情况,建议新发内容暂时返回403,等审核或做好处理之后,再返回正常状态的返回码。
• 站点迁移,或域名更换时,请使用301返回。
良好排序
涵盖网页上主要内容的title
网页的title用于告诉用户和搜索引擎这个网页的主要内容是什么,搜索引擎在判断一个网页内容权重时,title是主要参考信息之一。网页title是网页上主要内容的概括,搜索引擎可以通过网页标题迅速的判断网页的主题。每个网页的内容都是不同的,每个网页都应该有的title。
我们建议网页标题可以这样描述:
• 首页:网站名称 或者 网站名称_提供服务介绍or产品介绍
• 频道页:频道名称_网站名称
• 文章页:文章title_频道名称_网站名称
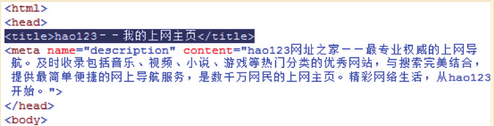
title指html文档中的<title>标签,而非文章的标题,以下面的形式放在html文档的<head>标签中
做法
• 每个网页应该有一个的标题,切忌所有的页面都使用默认标题
• 标题要主题明确,包含这个网页中重要的内容
• 简明精练,不罗列与网页内容不相关的信息
• 用户浏览通常是从左到右的,重要的内容应该放到title的靠前的位置
• 使用用户所熟知的语言描述。如果你有中、英文两种网站名称,尽量使用用户熟知的那一种做为标题描述
良好的内容建设
• 网站内容建设以服务网站核心价值为主,提供给搜索引擎收录的也应该是对自己核心价值有帮助的内容。内容建设要符合网站的主题,比如你的网站是一个it新闻网站,就不要放一堆的美女图片,除了浪费服务器资源以外,对网站的核心价值不会有任何帮助,看美女图片的人,不会对it新闻感兴趣。

某sns网站,注册用户是它重要的资源,也是它吸引新注册用户的主要依靠,搜索引擎中人名搜索是带给它潜在新用户的重要来源,他们提供给搜索引擎收录的注册用户人名资源,可以引导搜索引擎用户转化为它的注册用户。
• 网站的内容应该是面向用户的,搜索引擎只是网站的一个普通访客,提供符合用户需求的原创内容至关重要
• 写好锚文本
锚文本指在做链接时所使用的描述文字,用于告诉用户链接所链向网页的主题,锚文本描述越清楚,用户越容易理解指向网页的内容。
用户接触到你的网页是从其他网页的链接开始的,这个链接的描述能否让用户理解对吸引用户访问至关重要。如同普通用户一样,在搜索引擎刚发现一个新网页时,锚文本也对这个网页的描述是的参考因素。
• 为图片加alt说明
在网速较慢图片不能显示时让用户明白图片要传达的信息,也能让搜索引擎了解图片的内容。
• 资源较丰富的内容,可以以专题等更丰富的内容组织形式提供给用户,让用户以低的成本获取所有需要的信息。
• Web2.0类型的网站,应该充分利用自己的优势,让用户通过投票、评论等手段自己去判断资源的质量,这些对质量的判断,也可能会被搜索引擎用来判断资源的价值。
某视频站的投票,被顶多的视频,质量往往较高,用户可以参考投票信息,减少筛选成本
• 管理好web2.0等用户产生内容的产品,如果被作弊者利用,可能会影响整个站点的权重。
赢得用户对网站的
互联网上提供相同的内容、服务的网站有很多,在内容相同的时候,哪个网站会排在搜索引擎前面呢?决定性的因素就是。我们经常说的超链,就是的一种。
当你网站上的内容对用户有用时,用户会给别人,的形式可能多种多样:即时通讯工具上发给自己的朋友、在自己常泡的论坛里转帖、写博客很郑重的介绍、在自己网站上做友情链接等等。这些信息,都会被搜索引擎用来判断网页/网站价值的高低。适当的鼓励、引导用户你的网站,对网站在搜索引擎中的表现有很大帮助。
某视频网站的分享转帖等功能,可以让用户更方便的复制视频分享给其他用户,大大减轻了用户网站内容的成本,用户就更愿意。
良好展现
吸引眼球的Title
用户在百度网页搜索中搜索到你的网页时,title会做为重要的内容显示在摘要中,一个主题明确的title可以帮助用户更方便地从搜索结果中判断你网页上内容是否符合他需求。
做法:
• 标题要主题明确,包含这个网页中重要的内容
• 文章页title中不要加入过多的额外描述,会分散用户注意力
• 使用用户所熟知的语言描述
• 如果您的网站用户比较熟,建议将网站名称列到title中合适的位置,品牌效应会增加用户点击的机率
• 标题要对用户有吸引力
• 能让用户产生信任感
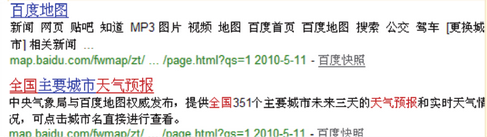
例子中的网页,提供全国主要城市的天气预报服务,个结果中,使用了百度地图默认的title,用户在搜索结果无法判断这个网站提供的内容是什么,也就不会点击这个结果,第二个结果中,title很明确的写明了所提供的内容,用户判断起来比较容易,选择这个结果的可能性比较大。
善用Meta description
Meta description是对网页内容的精练概括。如果description描述与网页内容相符,百度会把description当做摘要的选择目标之一,一个好的description会帮助用户更方便的从搜索结果中判断你的网页内容是否和需求相符。Meta description不是权值计算的参考因素,这个标签存在与否不影响网页权值,只会用做搜索结果摘要的一个选择目标。

Meta description是meta标签的一部分,位于html代码的<head>区
做法:
•网站首页、频道页、产品参数页等没有大段文字可以用做摘要的网页适合使用description
•准确的描述网页,不要堆砌关键词
•为每个网页创建不同的description,避免所有网页都使用同样的描述
•长度合理,不过长不过短
例子中,个没有应用meta description,第二个应用了meta description,可以看出个结果的摘要对用户基本没有参考价值,第二个结果的摘要可读性,可以让用户更了解网站的内容。
网站运营
目标=转化率
从搜索引擎获取流量的终目的是不断提高网站的核心价值。从搜索引擎获得的流量,有多少能转化为网站的核心价值,这就是转化率。内容型网站,忠实用户是核心价值,把搜索引擎用户转变为忠实用户就是终目的;SNS网站,注册用户是核心价值,让用户来你平台注册、活动就是终目的;如果你做电子商务网站,卖东西就是核心价值,把东西卖给顾客就是你要达到的目。在统计搜索引擎收益时,建议将转化率列为重要的衡量效果指标。
搜索引擎流量分析
搜索引擎用户在网站上的后续行为决定了这个用户会不会转化为忠实用户,分析用户行为可以为改进服务提供依据。以下几个指标可以的分析:
• 跳出率:只浏览一页便离开的用户的比例,跳出率高,通常代表网站对用户没有吸引力,也可能是网站内容之间的联系不够紧密。
• 退出率:用户从某个页面离开次数占总浏览量的比例。流程性强的网站,可以进行转换流程上的退出率分析,用于优化流程。比如购物网站,从商品页浏览-点击购买-登录-确认商品-付费这一系列的流程中每一步的退出率都记录下来,分析退出率异常的步骤,改进设计。
• 用户停留时间: 用户停留时间反映了网站粘性及用户对网站内容质量的判断。
以上是统计分析的基本的三个指标。行为分析可以看出用户的检索需求没有在你网站上得到满足,更进一步,思考如何的满足他的需求。
网站信任度
网站信用度指用户给予你网站的信任程度。用户对网站的信任度是用户在网站上进行活动的基础。
• 页面美观、整洁,有自己的风格
• 让可以很容易的了解到网站的背景
• 详细的网站介绍、联系方式,让用户可以方便的联系
• 用户评论、顾客反馈等信息,让原有的用户影响新用户
• 在网站设计中注重强化网站的品牌,让用户更了解、进而信任你的网站
不断强化品牌概念
互联网上的品牌建设是以优质内容、服务换来用户对网站内容的信任,让用户从一个从搜索引擎过客变成忠实用户的过程。在满足用户需求的同时适当的宣传品牌,不仅对用户在面对多个搜索结果时选择点击哪个有帮助,也会对口碑传播有很大的作用。
• 低层次,让用户知道他所获取的内容来自你的网站
• 进阶,让用户下次再想找这个信息时,能想到你的网站
• 终,能让用户在找同类内容时,能时间想到你的网站
作弊与惩罚
百度如何定义作弊
任何利用和放大搜索引擎的策略缺陷,利用恶意手段获取与网页质量不符的排名,引起用搜索结果质量和用户搜索体验下降的行为都会被搜索引擎当做作弊行为。
具体的作弊手法是无法穷尽的。互联网在动态的发展,搜索引擎也在动态的发展,作弊行为自然也是在动态的发展。基本的界定法则,就是这个行为的泛滥,是否会影响搜索系统,终伤害到用户的搜索体验。下面是一些我们近期发现的作弊形式:
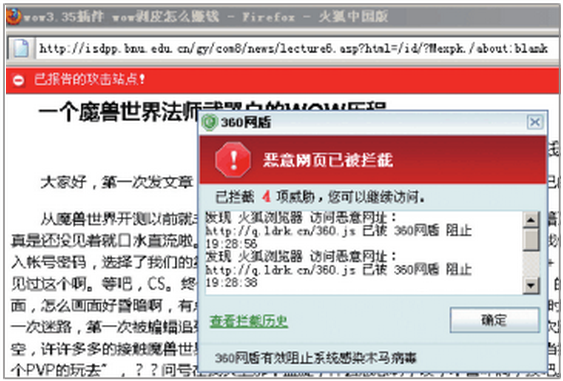
利用正常网站的漏洞,黑掉网站,偷偷放上作弊内容,通过搜索引擎获取流量,并利用木马盗取用户信息。

假冒知名公司官网,用户在其网站上发生交易完全没有。

利用bsp、bbs、分类信息等渠道,发布知名公司的客服电话,用户拨打电话后诈骗用户钱财。
作弊会受到怎样的惩罚
任何损害用户利益和搜索引擎结果质量的行为,都会受到搜索引擎的惩罚。作弊行为在不断的发展,我们的处理手段也在不断的变化,但始终都会维持“轻者轻罚,重者重罚”的原则:
• 对用户体验及搜索结果质量影响不大的,去除作弊部分获得的权值
• 对用户体验及搜索结果质量影响严重的,去除作弊部分获得的权值并降低网站的权重,直至从搜索结果中彻底清理掉
改正后能否解除惩罚?
惩罚不是目的,让互联网洁净才是目的。取消作弊行为的网站,百度都持欢迎态度。我们有完善的流程,会定期自动对作弊网站进行检测,大部分修正了作弊行为的网站,会在一定的观察期满后自动解除惩罚。
Q&A
百度商业推广和自然搜索结果的关系是什么?
必须要说明一点的是,“竞价排名”这个说法,带有一些误导意味。所以,现在百度对这个业务改称“百度推广”,而不是“竞价排名”了。
百度的商业推广和自然搜索,是由完全独立的两个部门分别运营两套独立系统,参加商业推广的网站,在自然结果中一视同仁,没有任何特殊处理。百度的商业推广(包括左侧和右侧)和自然搜索(从前的特征是后面带一个链接,叫百度快照;但现在大部分的开放搜索结果也是不带快照链接的)是两个完全独立的系统。商业推广的原理,不是“给了钱,自然结果中的某些结果就可以排得更靠前”,而是“用户的关键词被分发到两个独立系统中,分别产生了商业结果和自然结果,商业结果在前,自然结果在后,就构成了百度的搜索结果”。
关于这一点的认知,误会很深,所以做专门的说明。“不给钱就干掉”的传言,就是在这样的背景下产生的。
更换空间怎么办?
参照以下步骤:
• 开通新的空间,并将网站完整的迁移到新空间,并保持流畅访问
• 将域名的服务器指向更新为新空间的ip
• 旧空间能持续访问一段时间
• 关注新空间的访问日志,等Baiduspider的抓取完全迁移到新空间后,停止旧空间的服务。
百度是否支持nofollow?
百度支持< a rel="nofollow" href="url">123</a>、<meta name="robots" content="nofollow">两种写法的nofollow,带有nofollow属性的url,不会传递权值。
百度支持不支持https协议?
百度目前只能收录少部分https网页,大部分https网页无法收录。网站首页和对所有用户都公开的内容页面,建议不要使用https协议,如果非用不可,尽量将首页和重要页面做个http可访问版,方面百度收录。
Site语法查到的结果数是百度收录的网页数量吗?
site语法得到的搜索结果数,只是一个估算的数值,仅供参考。
site语法设定的初衷,其实是期望用户可以设定约束搜索范围,实现更加精准的搜索。这同intitle,inurl,本质上是相同的。而在这些语法下的结果数,和常规搜索一样,都是“估值”,而非值。因此,很有可能site下的“结果数”减少了,实际被索引数却可能增加了。
修改网站标题是否会对网站排名带来消极影响?
title是极重要的内容。大幅修改,可能会带来大幅波动。所以请慎重对待网页标题。建议按照我们上面所的写法,实事求是的将页面主旨反映在标题中即可,如无必要,尽量不做大幅修改。
修改首页的meta description是否会受到惩罚?
meta description只是摘要的一个选择目标,修改meta description只会影响摘要。我们鼓励大家通过meta description来撰写网站的简介。只是过于频繁的修改,未必会及时的反馈在摘要中。
百度建议URL静态化吗?
URL是动态还是静态,对百度没有影响,我们没有任何歧视动态url的策略。以前之所以说搜索引擎处理不好动态url,主要是因为动态url中参数过多,很容易制造出大量内容相同、url不同的无限循环的“黑洞”,spider陷入其中,浪费大量的资源。现在我们已经能比较完美的解决这个问题。
动态url好象我们建议的那样,尽量减少动态url中包含的变量参数,一方面可以减短url长度,另一方面,也减少把Baiduspider带入“黑洞”的风险。
百度支持哪些Robots Meta标签?
百度支持nofollow、noarchive两种种meta标签。
要防止所有搜索引擎显示您网站的快照,请将此元标记置入网页的<HEAD> 部分:<meta name="robots" content="noarchive">
如果您不想搜索引擎追踪此网页上的链接,且不传递链接的权重,请将此元标记置入:<meta name="robots" content="nofollow">
站点启用CDN、反向代理、开启gzip压缩等服务会不会影响搜索引擎收录?
Baiduspider对站点的抓取方式和普通用户访问一样,只要普通用户能访问到的内容,我们就能抓取到。不管是用什么技术,只要能用户能流畅的访问网站,对搜索引擎就没有影响。我们建议尽量选择有实力的服务商和成熟的技术,不成熟的技术容易导致访问不稳定,这就有可能影响搜索引擎的抓取了。
百度对使用海外空间的中文网站有歧视吗?
百度对海外站点没有歧视。但Baiduspider服务器在国内,国内普通用户访问受限的内容,Baiduspider一样会搞不定,只要国内能正常访问,我们就会一视同仁。
百度如何对待一个主题完全更换、改版的网站?
如果是内容发生根本性变化,则理论上会被视为一个全新网站,旧有超链失效。
联系与反馈
您可以通过投诉反馈中心
http://tousu.baidu.com/webmaster/add
把问题反馈给我们,虽然我们无法逐一回复,但我们会有专人整理反馈,并将问题转交给相关的工程师认真分析。
